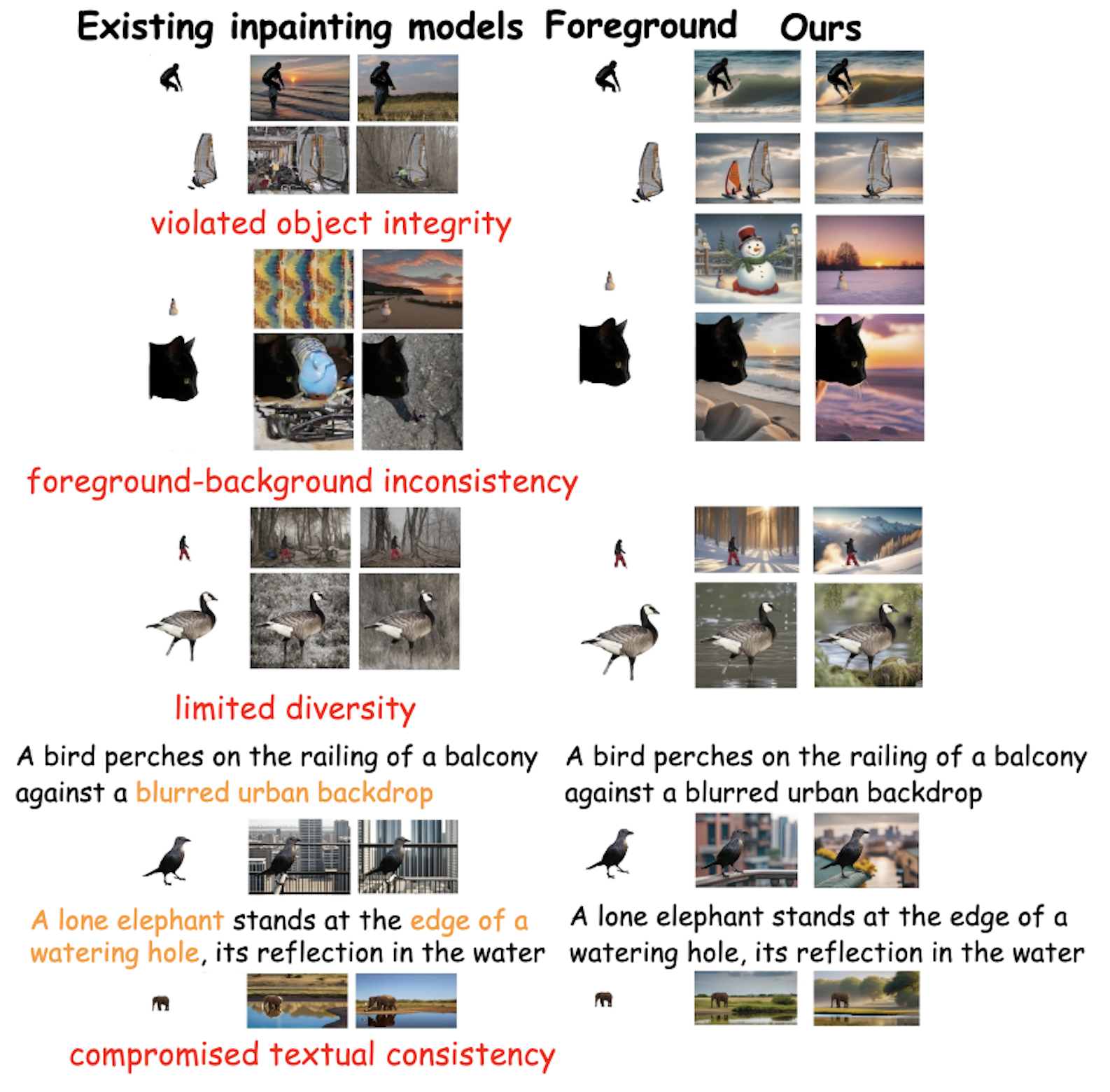
Recent advancements in image-conditioned image generation have demonstrated substantial progress. However, foreground-conditioned image generation remains underexplored, encountering challenges such as compromised object integrity, foreground-background inconsistencies, limited diversity, and reduced control flexibility. These challenges arise from current end-to-end inpainting models, which suffer from inaccurate training masks, limited foreground semantic understanding, data distribution biases, and inherent interference between visual and textual prompts. To overcome these limitations, we present Anywhere, a multi-agent framework that departs from the traditional end-to-end approach. In this framework, each agent is specialized in a distinct aspect, such as foreground understanding, diversity enhancement, object integrity protection, and textual prompt consistency. Our framework is further enhanced with the ability to incorporate optional user textual inputs, perform automated quality assessments, and initiate re-generation as needed. Comprehensive experiments demonstrate that this modular design effectively overcomes the limitations of existing end-to-end models, resulting in higher fidelity, quality, diversity and controllability in foreground-conditioned image generation. Additionally, the Anywhere framework is extensible, allowing it to benefit from future advancements in each individual agent.
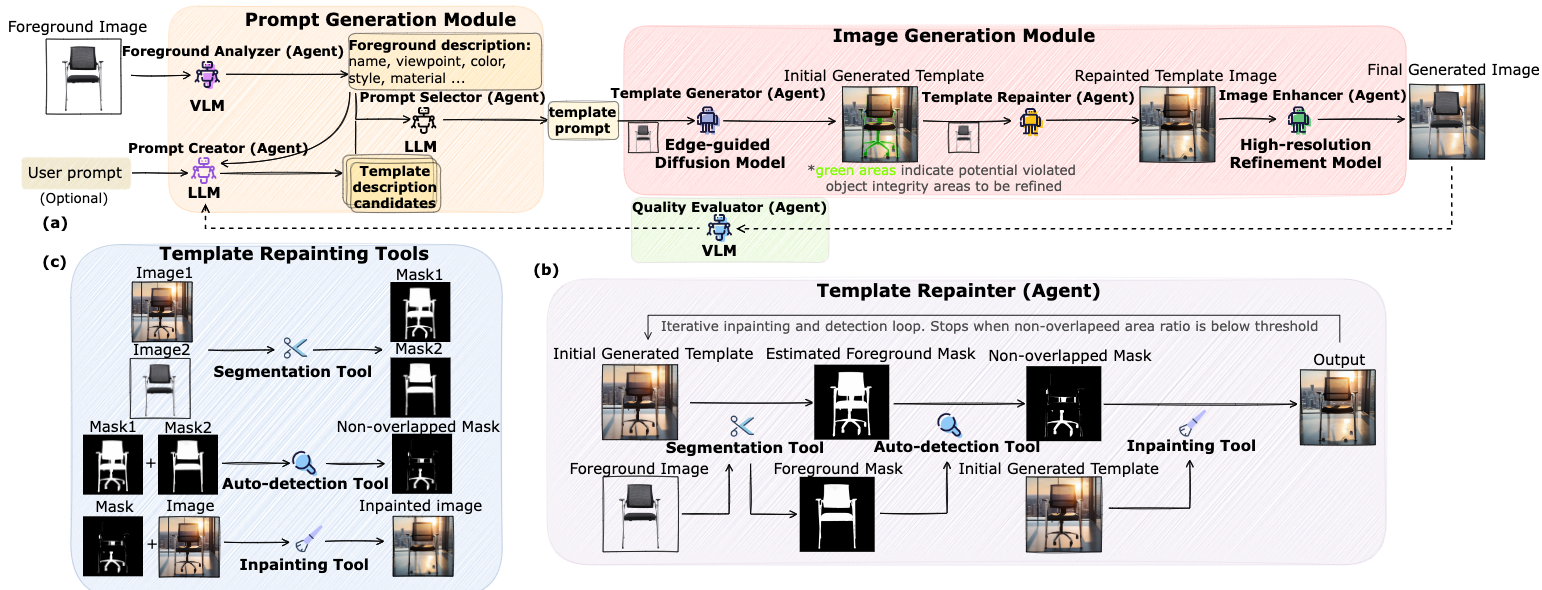
Anywhere is a multi-agent image generation framework comprising agents of various modalities, such as large language model, visual language model, controlled image generation model, and inpainting model. Its workflow encompasses three modules: the prompt generation module, the image generation module, and the quality evaluator, as illustrated in Figure Anywhere achieves background generation by processing images through modules utilizing diverse agents.

We compare our approach to advanced inpainting models on foreground-conditioned image generation tasks in both text-free (I2I) and text-guided (TI2I) scenarios. These results are generated using unconstrained, in-the-wild foreground images. Red color indicates missing elements in generated images. The inpainting models used for comparison include HD-Painter (HDP), BrushNet (BN), and Stable Diffusion 2.0 Inpainting (SDI).


The prompt generation module (PG). It reveals that without the prompt generation module, our system tends to produce less diverse results with uniform empty backgrounds.

The Template Repainter. As shown, the repainting agent contributes to mitigating the “over-imagination” issue.

The Image Enchancer. This agent enhances the overall quality of the composite image, focusing on fine details, color balance, and smooth transitions.

The Quality Evaluator. As shown, the mechanism of feedback-based regeneration significantly improves the quality of the final outcomes.

More qualitative results on text-free scenarios (I2I).

More qualitative results on text-guided scenarios (TI2I).
@article{xie2024anywhere,
title={Anywhere: A Multi-Agent Framework for Reliable and Diverse Foreground-Conditioned Image Inpainting},
author={Xie, Tianyidan and Ma, Rui and Wang, Qian and Ye, Xiaoqian and Liu, Feixuan and Tai, Ying and Zhang, Zhenyu and Yi, Zili},
journal={arXiv preprint arXiv:2404.18598},
year={2024}
}